今天突然来了兴趣,学了下在C#中调用Rust的“奇技淫巧”,因为向来Rust都以高性能,内存安全著称,之前也稍微了解过一些,所以突发奇想就来实际对比一下同一个算法,这两个哪个会更快?
免责声明:自己随便写的,测着玩的,请勿较真,图一乐即可~
测试条件:
- 代码环境:C# .NET 10,Rust edition 2024
- 编译:C# 与 Rust 均在 Release 模式下,Rust 没有开
-C target-cpu=native - 系统:Win11 专业版
- CPU:AMD Ryzen AI 9 H 365 w/ Radeon 880M (2.00 GHz)
- 内存:32G,5600MT/s
以下方法中,C# 为了确保 JIT 编译和 DLL 加载完成,消除首次调用开销,进行了 1000 次预热,同样的,Rust 为了避免 FFI 第一次加载动态链接库时可能有一些加载和初始化开销,也进行了 1000 次预热。
且测试结果同样都是执行 50_000_000 次/循环。
简单的累加计算:
C#:
// C# 版本的累加计算函数
private static long CalculateSumCSharp(long iterations)
{
long sum = 0;
for (var i = 1; i <= iterations; i++)
{
sum += i;
}
return sum;
}
Rust:
/// 计算从 1 到 `iterations` 的所有整数之和。
///
/// # 参数
/// * `iterations` - 迭代次数(上限值)。
///
/// # 返回
/// 所有整数之和。
#[unsafe(no_mangle)]
pub extern "C" fn calculate_sum_rust(iterations: i64) -> i64 {
let mut sum: i64 = 0;
for i in 1..=iterations {
sum += i;
}
sum
}
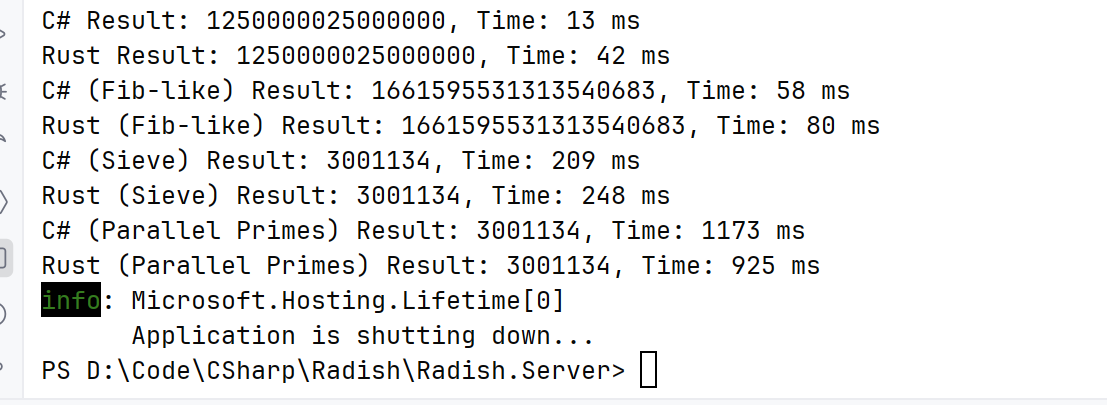
执行结果:
{
"iterations": 50000000,
"cSharpExecutionTimeMs": 13,
"rustExecutionTimeMs": 42,
"cSharpResult": 1250000025000000,
"rustResult": 1250000025000000,
"message": "C# Execution Test Victory!"
}
斐波那契模拟计算:
C#:
// C# 版本的斐波那契模拟计算
private long CalculateFibonacciLikeCSharp(long iterations)
{
if (iterations <= 0)
{
return 0;
}
if (iterations == 1)
{
return 1;
}
long a = 0;
long b = 1;
long resultSum = 0; // 用于累计一个结果,避免编译器优化掉整个循环
for (long i = 2; i <= iterations; i++)
{
long nextFib = a + b;
a = b;
b = nextFib;
resultSum += nextFib % 100; // 模拟一个操作,并控制数值大小防止溢出
}
return a + b + resultSum; // 返回一个最终的校验和
}
Rust:
/// 模拟计算斐波那契数列的第 `iterations` 项,但只进行迭代次数。
///
/// 实际返回的是每次迭代中计算出的两个值之和,不代表真正的斐波那契数。
/// 主要目的是模拟 CPU 密集型计算。
#[unsafe(no_mangle)]
pub extern "C" fn calculate_fibonacci_like_rust(iterations: i64) -> i64 {
if iterations <= 0 {
return 0;
}
if iterations == 1 {
return 1;
}
let mut a: i64 = 0;
let mut b: i64 = 1;
let mut result_sum: i64 = 0; // 用于累计一个结果,避免编译器优化掉整个循环
for _ in 2..=iterations {
// 从第 2 项开始迭代,因为 0 和 1 项已初始化
let next_fib = a + b;
a = b;
b = next_fib;
result_sum += next_fib % 100; // 模拟一个操作,并控制数值大小防止溢出,同时避免编译器过度优化
}
// 返回一个有意义的值,但不是真正的斐波那契数,因为中间值可能溢出
// 关键在于循环被执行了 iterations 次,并且内部有加法和赋值操作
a + b + result_sum // 返回一个最终的校验和,确保所有计算未被优化掉
}
执行结果:
{
"iterations": 50000000,
"cSharpExecutionTimeMs": 58,
"rustExecutionTimeMs": 80,
"cSharpResult": 1661595531313540600,
"rustResult": 1661595531313540600,
"message": "C# Execution Test Victory!"
}
埃拉托斯特尼筛法:
C#:
// C# 版本的埃拉托斯特尼筛法
private long CountPrimesSieveCSharp(long limit)
{
if (limit < 2)
{
return 0;
}
bool[] isPrime = new bool[limit + 1];
for (int i = 0; i <= limit; i++)
{
isPrime[i] = true;
}
isPrime[0] = false;
isPrime[1] = false;
long count = 0;
for (long p = 2; p * p <= limit; p++)
{
if (isPrime[p]) // 如果 p 是质数
{
// 将 p 的所有倍数标记为非质数
for (long i = p * p; i <= limit; i += p)
{
isPrime[i] = false;
}
}
}
// 统计质数数量
for (long i = 2; i <= limit; i++)
{
if (isPrime[i])
{
count++;
}
}
return count;
}
Rust:
/// 使用埃拉托斯特尼筛法计算小于等于 `limit` 的质数数量。
///
/// # 参数
/// * `limit` - 查找质数的上限。
///
/// # 返回
/// 小于等于 `limit` 的质数数量。
#[unsafe(no_mangle)]
pub extern "C" fn count_primes_sieve_rust(limit: i64) -> i64 {
if limit < 2 {
return 0;
}
// 创建一个布尔向量,初始都为 true
// 注意:Vec<bool> 在 Rust 中被特殊优化,可能不会是每个 bool 占一个字节
// 为了和 C# 的 bool[] 行为更接近,或者避免某些编译器优化,可以使用 Vec<u8> 或 Vec<char>
// 但对于这种场景,Vec<bool> 通常是没问题的。
let mut is_prime = vec![true; (limit + 1) as usize];
// 0 和 1 不是质数
is_prime[0] = false;
is_prime[1] = false;
let mut p: i64 = 2;
while p * p <= limit {
// 如果 is_prime[p] 仍然为 true,则它是一个质数
if is_prime[p as usize] {
// 将 p 的所有倍数标记为 false
let mut i = p * p;
while i <= limit {
is_prime[i as usize] = false;
i += p;
}
}
p += 1;
}
// 统计质数数量
let mut count: i64 = 0;
for i in 2..=limit {
if is_prime[i as usize] {
count += 1;
}
}
count
}
执行结果:
{
"iterations": 50000000,
"cSharpExecutionTimeMs": 209,
"rustExecutionTimeMs": 248,
"cSharpResult": 3001134,
"rustResult": 3001134,
"message": "C# Execution Test Victory!"
}
并行计算小于等于 50_000_000 的质数数量(通过试除法):
C#:
// 优化过的试除法判断一个数是否为质数。
private bool IsPrime(long n)
{
if (n <= 1)
{
return false;
}
if (n <= 3)
{
return true;
}
if (n % 2 == 0 || n % 3 == 0)
{
return false;
}
long i = 5;
while (i * i <= n)
{
if (n % i == 0 || n % (i + 2) == 0)
{
return false;
}
i += 6;
}
return true;
}
// 并行计算小于等于 `limit` 的质数数量(通过试除法)。
private long CountPrimesParallelCSharp(long limit)
{
if (limit < 2)
{
return 0;
}
long totalPrimeCount = 0; // 使用 Interlocked 保护
// 使用 Parallel.For 进行并行迭代
// 默认使用 Environment.ProcessorCount 作为最大并发度
Parallel.For(2, limit + 1, (n) =>
{
if (IsPrime(n))
{
// 原子地增加计数器
Interlocked.Increment(ref totalPrimeCount);
}
});
return totalPrimeCount;
}
Rust:
/// 优化过的试除法判断一个数是否为质数。
fn is_prime(n: i64) -> bool {
if n <= 1 {
return false;
}
if n <= 3 {
return true;
}
if n % 2 == 0 || n % 3 == 0 {
return false;
}
let mut i = 5;
while i * i <= n {
if n % i == 0 || n % (i + 2) == 0 {
return false;
}
i += 6;
}
true
}
/// 并行计算小于等于 `limit` 的质数数量(通过试除法)。
///
/// # 参数
/// * `limit` - 查找质数的上限。
///
/// # 返回
/// 小于等于 `limit` 的质数数量。
#[unsafe(no_mangle)]
pub extern "C" fn count_primes_parallel_rust(limit: i64) -> i64 {
if limit < 2 {
return 0;
}
let prime_count = AtomicI64::new(0);
// Rayon 会自动根据可用的核心数进行并行化。
// 如果 limit 很小,rayon 会自动选择串行执行,避免并行开销。
(2..=limit).into_par_iter()
.for_each(|n| {
if is_prime(n) {
prime_count.fetch_add(1, Ordering::Relaxed);
}
});
prime_count.load(Ordering::Relaxed)
}
执行结果:
{
"iterations": 50000000,
"cSharpExecutionTimeMs": 1173,
"rustExecutionTimeMs": 925,
"cSharpResult": 3001134,
"rustResult": 3001134,
"message": "Rust Execution Test Victory!"
}
四把计算,也就只有多线程 Rust 才赢了一把,之前 .NET10 听说快了很多,没想到确实可以
当然,也有可能是我的代码不严谨,或者说并没有写到两种语言的精髓,或者是 FFI 拖慢了Rust 的速度,就图一乐吧
这是实测:
最后,贴上我和 Gemini 讨论过程中的搞笑的点:


哈哈哈,尤其是这个:
