为什么是精馏系统
精馏系统设计不仅仅是塔设备,包括物性数据、气液平衡数据、回流量vs理论塔板数、热力学方法、节能优化、塔板/填料效率、塔径选择、水力学确定、塔板和填料等内构件的设计等等。
精馏设计导致精馏塔异常的占比(经验值)仅为7%左右,虽然在设计过程中找问题的成功率不高,但是问题的解决还是需要对原始设计有足够的理解和认识。
基础物性数据
CAS 号是组分的唯一标识符
沸点在不同的物性数据库中存在差异
在精细化工模拟中存在的问题:反应产物杂质多、组分无法确定、关键组分有同分异构、存在共沸、均相或非均相等
物性分析 的重点有这么几项:熔点、密度、发泡、颗粒物、粘度、表面张力、热敏、临界参数,其对应的影响因素如下:
| 物性 | 影响因素 |
|---|---|
| 熔点 | 凝固点,操作温度考虑 |
| 密度 | 精馏压降 |
| 发泡性 | 影响气液传质,发泡因子(经验数据) |
| 颗粒物 | 堵塞塔内件 |
| 粘度 | 流动性差,带来液泛,影响传质效率 |
| 表面张力 | 填料塔的润湿和传质 |
| 热敏性 | 热稳定性、操作温度、停留时间、传热等考虑 |
| 临界参数 | 操作温度和压力 |
基础物性数据来源:
| 数据来源 | 举例 |
|---|---|
| 模拟软件 | Aspen、PRO/II、COMSOThermo等 |
| 网络 | 百度百科、化工百科、ChemicalBook等 |
| 化工手册 | 化学工程手册、Perry化学手册等 |
| 文献 | 知网、维普、万方、SCI HUB等 |
| 专业数据库 | NIST、DDB、STN、DIPPR、THERMODEX、CASFinder等 |
| 企业内部数据库 | 实验、小试、中试、生产数据等 |
Aspen
- 纯组分数据库(Aspen Properties Database)
- 数据量:覆盖超过5,000种纯物质,包含气体、液体、固体(如CO₂、H₂O、NaCl等)。
- 关键参数:临界性质(Tc, Pc)、蒸汽压、热容、粘度、导热系数等,支持多种状态方程(PR、SRK)和活度系数模型(NRTL、UNIQUAC)。
- 特殊功能:支持虚拟组分(如石油馏分)和自定义物性估算方法(UNIFAC基团贡献法)。
- 电解质数据库(Aspen Electrolytes)
- 覆盖范围:包括离子(H⁺、OH⁻、Na⁺、Cl⁻等)、离子对(如NaCl(aq))和反应平衡(如酸碱解离)。
- 应用场景:脱硫、废水处理、电化学过程(如电解水制氢)。
- 特点:内置Pitzer模型等复杂电解质热力学方法,支持高浓度离子体系的活度系数计算。
- 固体数据库(Aspen Solid)
- 数据类型:颗粒密度、粒径分布、孔隙率、热导率等。
- 单元操作支持:流化床、结晶器、固体分离设备(如离心机)。
- 行业应用:催化剂设计(如FCC催化剂)、矿物加工(如碳酸钙煅烧)。
- 专用行业数据库
- 聚合物数据库:包含单体(乙烯、丙烯)、共聚物(如PET)、链段增长动力学参数。
- 制药数据库:溶剂的Hansen溶解度参数、API(活性药物成分)的结晶动力学数据。
- 特点:与行业标准工具(如聚合物分子量分布分析)深度集成。
- 用户自定义数据库
- 实现方式:通过
User Properties或Databank Manager导入实验数据(如自定义活度系数、反应速率)。 - 灵活性:支持文本文件、Excel表格或直接输入,但需注意单位一致性和模型兼容性。
- 实现方式:通过
以上数据来自模型 Deepseek-R1,回答时间:2025 03-06 10:33
还有另一种分类方法:系统数据库(system databanks)、内置数据库(inhouse databanks)以及用户收据库(user databanks)。
PRO/II
- 标准组分库
- 数据量:约3,000种常见物质,侧重石油化工(烃类、硫化物)和无机物(H₂、N₂、CO₂)。
- 热力学模型:内置SRK、PR、Chao-Seader等模型,优化了气液平衡(VLE)计算速度。
- 电解质数据库
- 简化模型:基于扩展的Debye-Hückel方程,适用于低浓度电解质(如锅炉水处理)。
- 局限性:对高浓度或复杂离子相互作用的模拟精度弱于Aspen。
- 石油馏分数据库
- 原油表征:支持通过ASTM D86/D2887蒸馏曲线生成虚拟组分,自动计算分子量和密度。
- 炼油优化:内置典型原油(如Brent、Arab Light)的馏分数据,快速搭建常减压蒸馏模型。
- 热力学模型参数库
- 预置参数:包含数千种二元交互参数(如CH₄-H₂O的交互系数),减少用户调试工作量。
- 收敛性:针对炼油和天然气液化的常见体系(如LNG低温分离)优化了模型稳定性。
- 用户自定义数据库
- 操作便捷性:通过
User Component向导逐步输入物性(如沸点、密度),支持Excel批量导入。 - 局限性:自定义固体物性或复杂反应动力学时功能较Aspen弱。
- 操作便捷性:通过
以上数据来自模型 Deepseek-R1,回答时间:2025 03-06 10:33
补充说明另一种分类方式:PROII库(SIMSCI)、Process program库(PROCESS)、AIChE DIPPR库(DIPPR)和电解质库(OLILIB)。
关键差异与使用建议
- 行业侧重
- Aspen Plus:适合跨行业复杂体系(如制药反应器、聚合物合成、CO₂捕集)。
- PRO/II:在炼油分馏、天然气脱硫、LNG液化等场景中更高效。
- 电解质与固体处理
- Aspen:可处理高浓度离子体系(如浓硫酸稀释热计算)和复杂固体颗粒(如流化床催化剂磨损)。
- PRO/II:电解质功能较基础,固体处理通常需依赖插件或简化假设。
- 用户自定义体验
- Aspen:功能强大但学习曲线陡峭(需熟悉物性方法选择规则)。
- PRO/II:界面友好,适合快速添加石油馏分或自定义轻组分。
- 热力学模型灵活性
- Aspen:支持混合模型(如气相用PR方程,液相用NRTL活度系数)。
- PRO/II:模型组合灵活性较低,但预置参数更贴合石油行业需求。
| 维度 | Aspen Plus | PROii |
|---|---|---|
| 覆盖行业 | 化工、制药、高分子、能源(综合性强) | 石油炼制、天然气处理(行业纵深突出) |
| 电解质处理 | 模型复杂,适合高精度离子体系模拟 | 简化模型,适合基础应用 |
| 固体处理 | 支持结晶、颗粒物性等深度功能 | 功能较基础,侧重流体模拟 |
| 用户自定义 | 功能强大但操作复杂 | 界面友好,Excel集成便捷 |
| 典型应用 | 精细化工流程、反应器设计、聚合物生产 | 炼油分馏、天然气液化、管线输送模拟 |
以上数据来自模型 Deepseek-R1,回答时间:2025 03-06 10:33
数据准确性
- 准确性:模拟“再现”实际生产的能力
- 精度:软件解方程的能力
准确性≠精度,原因在于 物性数据是否准确。
二元交互参数
在研究混合物的时候,如果分子间的相互作用不是理想状态,就要用二元交互参数来矫正它们之间的相互作用。
二元参数来自于估算方法 UNIFAC,也可以来自于实验数据 VLE、LLE、γoo等;
VLE决定精馏塔的性能,对于理想混合物,VLE只与组分的分压有关;
非理想混合物:应假定现实世界的分离是非理想的,否则要求使用修正因子,称为 活度系数,它与温度和压力有关。
对于一种混合物,活度系数是确定的。
相图
分为:理想体系、均相、非均相;
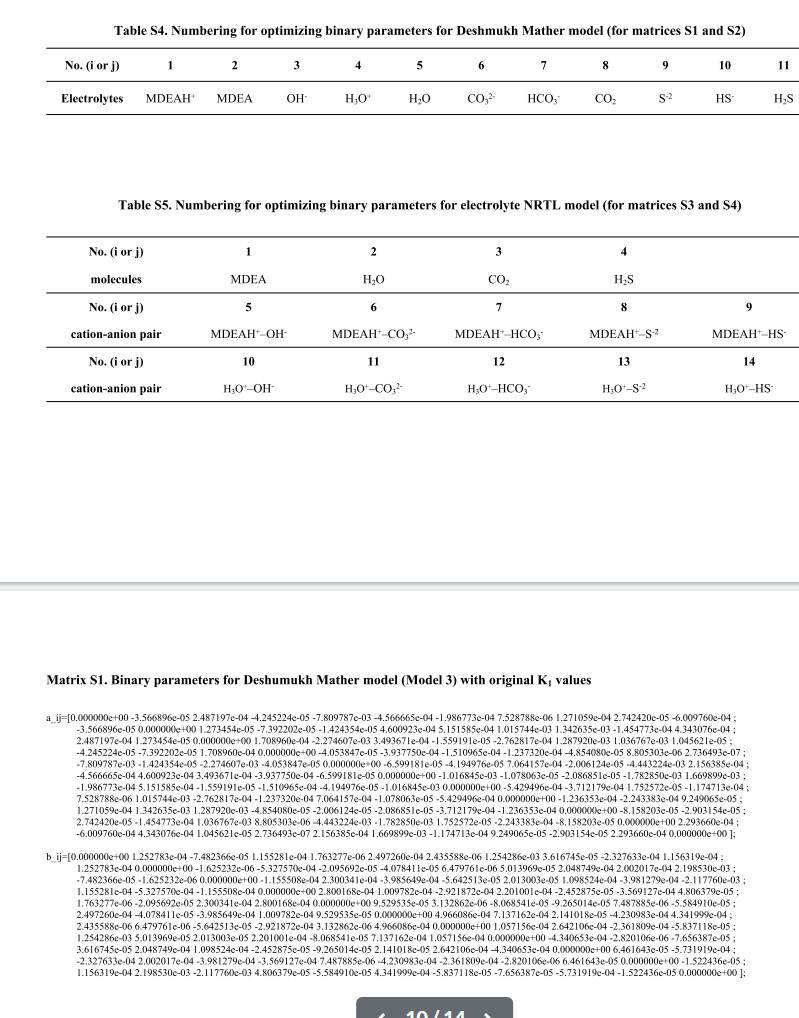
HCL/H2O不考虑电解质Txy相图:
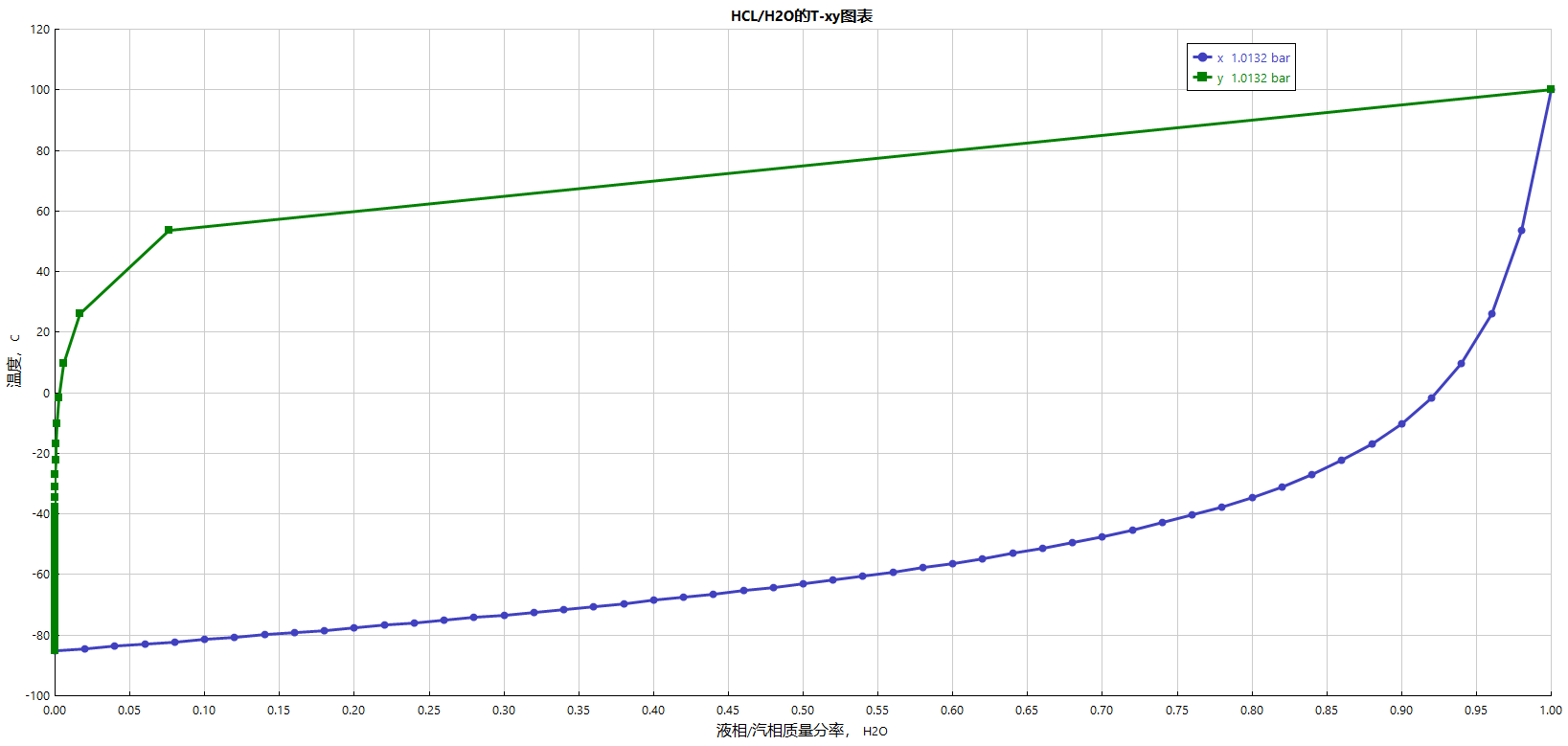
HCL/H2O考虑电解质Txy相图:
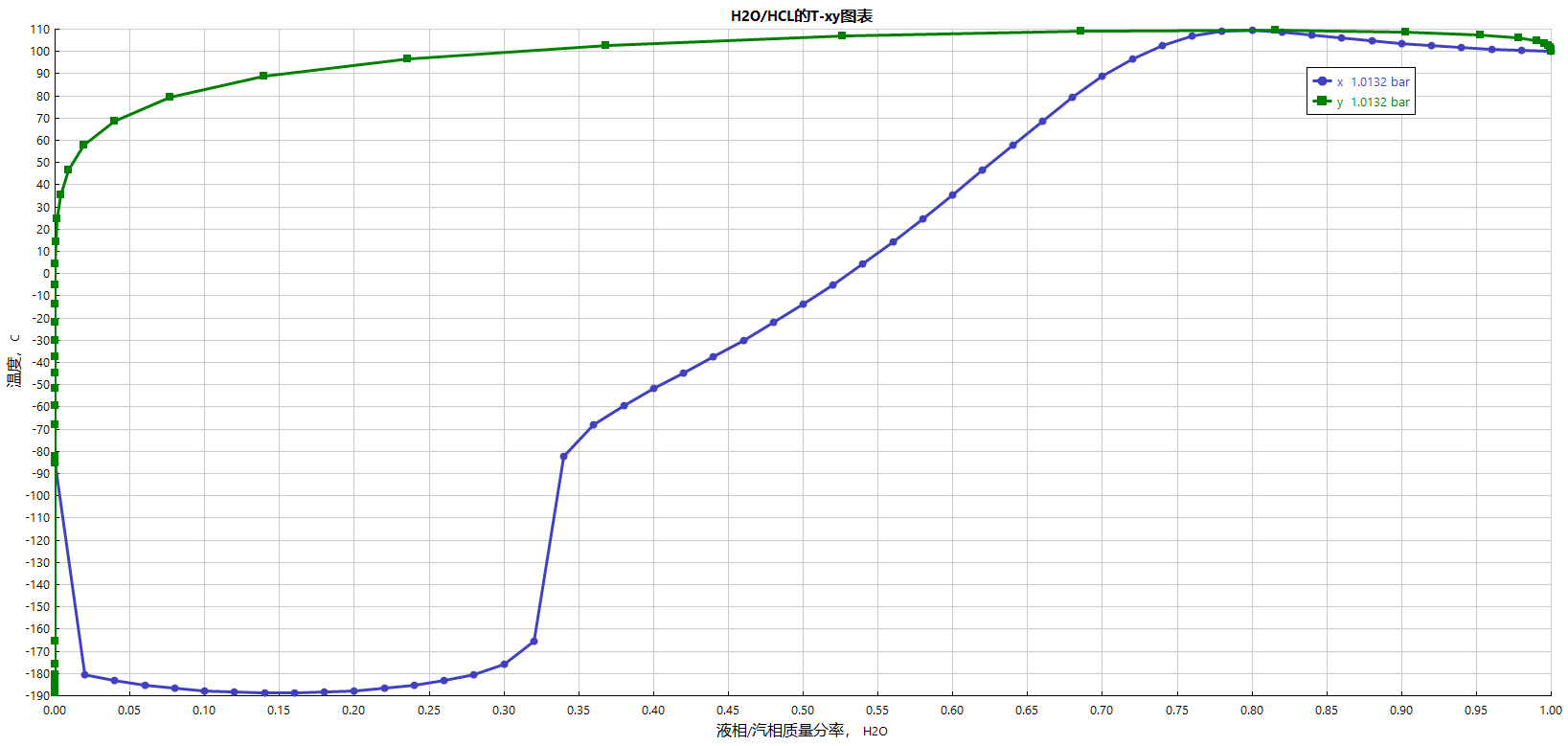
HCL/H2O考虑电解质&参数修正后Txy相图:
还有一个案例:某体系模拟结果分层,实际实验结果不分层,原因:Aspen中实验数据点太少,导致生成相图时曲线被拉伸成为了非均相体系;
Aspen数据库详解参考:精馏培训-2-Aspen数据库详解
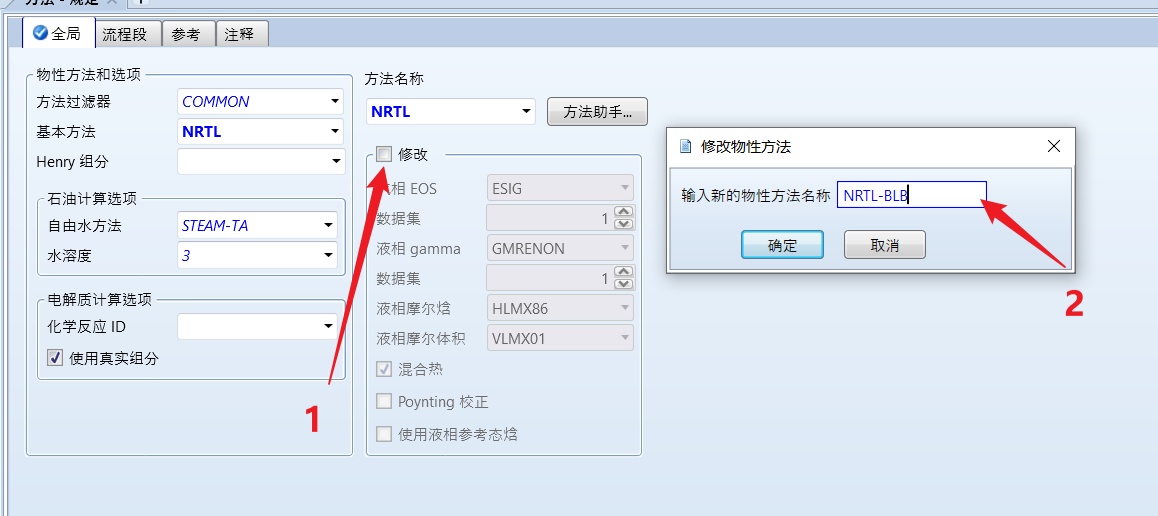
修改内置物性方法
在物性方法选择界面,勾选 修改,在弹出的对话框中输入自定义的物性方法名称,不要与内置的现有方法冲突即可:
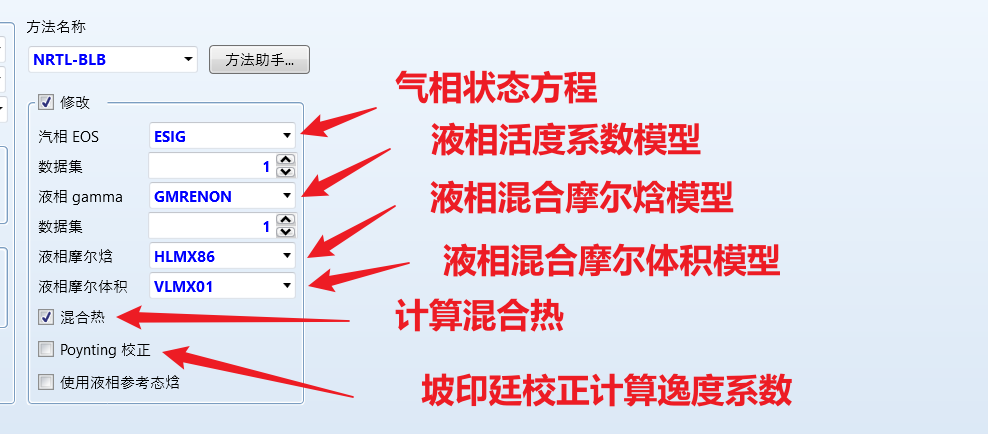
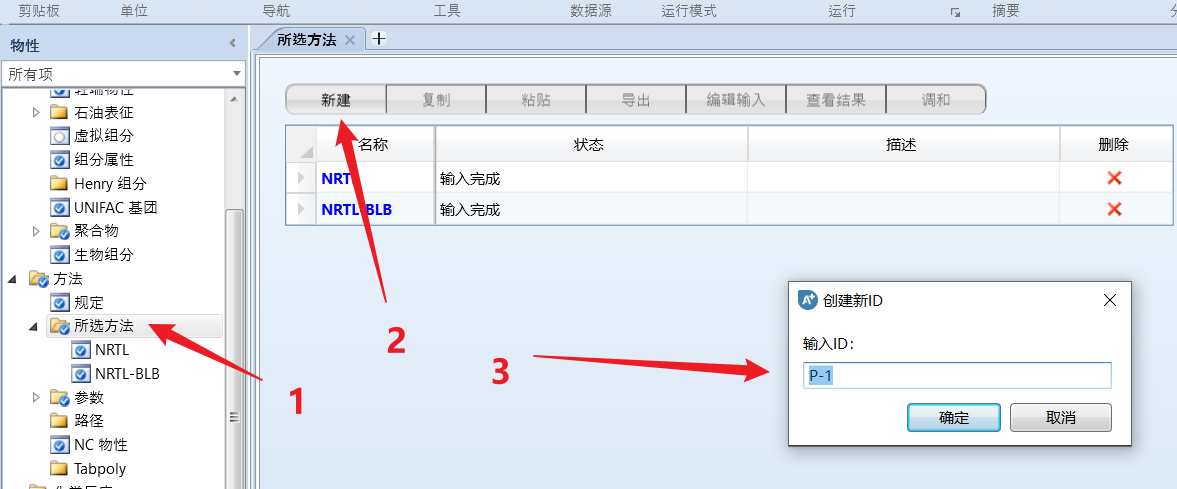
高级参数修改:进入 方法 - 所选方法,点击 新建,输入名称:
选择 基准模型,在此基础上进行修改参数:
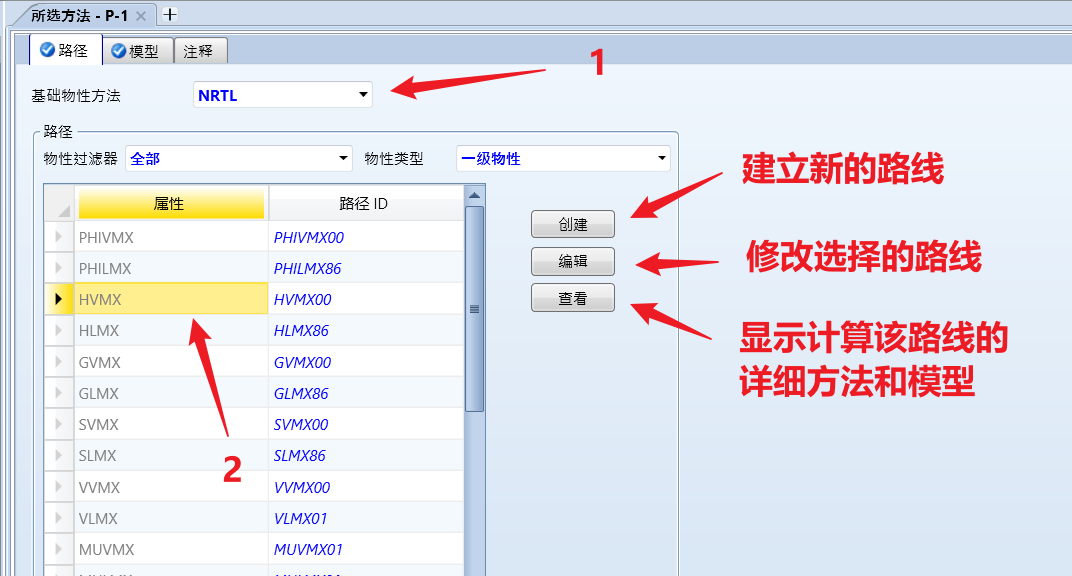
点击 模型 选项卡,可以规定新的物性模型,可以修改物性计算模型和使用的数据集:
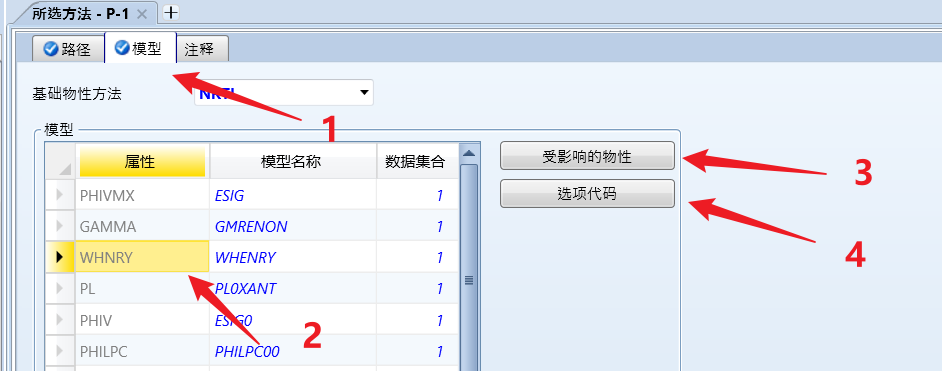
点击 受影响的物性 可以查看该模型影响的一系列物性,点击 选项代码 查看模型选项代码。